
Claude Code skills turn agent mistakes into team memory
Anthropic's June 2026 Claude Code skills post is more than guidance for better prompt folders. This article explains how skills function as task-triggered procedural memory, why verification skills matter most, and what plugin marketplaces imply for enterprise agent operations.

Research Brief
Claude Code skills look small on the surface: a folder, a
SKILL.md file, maybe a few scripts and examples. Anthropic's June 3 post argues that this small unit has become one of Claude Code's most-used extension points, with hundreds of internal skills active at Anthropic 1. The interesting part is not that Claude can read another markdown file. It is that Anthropic is treating skills as the place where a team stores procedural memory: the mistakes Claude keeps making, the verification steps humans trust, the internal tools it should call, and the distribution path for all of that knowledge.That makes skills a quieter but important Claude Code release. They move context engineering away from giant, always-loaded instruction blocks and toward small, task-triggered packets of operational knowledge.
A skill is a folder, not a prompt
Anthropic defines a Claude Code skill as a folder of instructions, scripts, and resources that an agent can discover and use to complete specialized tasks more accurately and efficiently 1. The Claude Code docs make the same point from the runtime side: a skill's body loads only when it is used, so long reference material has little context cost until the task needs it 2.
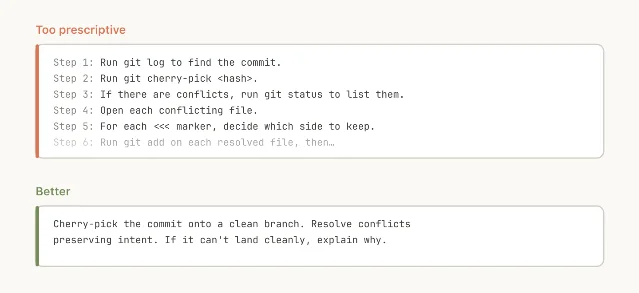
That is the design move.
CLAUDE.md remains useful for facts and always-on conventions. Skills are for procedures. The difference matters because many agent failures do not come from a lack of general intelligence. They come from missing the local rule that a human teammate would remember: use this internal CLI, never trust that staging response, check this table before you answer, run the browser verifier before declaring the UI fixed.Anthropic says its internal catalog now falls into nine categories: library and API reference, product verification, data and analysis, business automation, scaffolding and templates, code quality and review, CI/CD and deployment, incident runbooks, and infrastructure operations 1. That taxonomy is useful because it separates skills from generic prompt packs. The durable ones encode a repeatable job.

The highest-value skills teach verification
The strongest claim in the post is about verification. Anthropic says product-verification skills have had the most measurable impact on Claude's output quality internally, enough that it can be worth having an engineer spend a week making those skills excellent 1. That is consistent with a broader point Anthropic made the same day in its self-service analytics write-up: analytics agents fail less because of SQL generation and more because of entity ambiguity, stale data, and retrieval failure 3.
The analytics post gives numbers. Anthropic says 95% of its business analytics queries are automated via Claude with about 95% aggregate accuracy, and that without skills, Claude's ability to answer analytics questions did not exceed 21% on its evals. Adding skills took the number above 95% in aggregate, with some domains regularly around 99% 3.
| Failure mode | Skill response Anthropic describes | Why it matters |
|---|---|---|
| Ambiguous concepts | Route the agent to canonical datasets, semantic layers, and domain reference docs 3 | The agent stops choosing among forty plausible definitions of a metric. |
| Stale procedures | Colocate skill markdown with the models or systems they describe, then make PRs update both together 3 | The skill becomes part of the engineering maintenance surface, not a wiki page left to rot. |
| Weak verification | Use adversarial review and evals, with Anthropic reporting a 6% accuracy gain from adversarial validation at the cost of 32% more tokens and 72% higher latency 3 | Teams can decide when correctness is worth extra compute instead of treating all tasks the same. |
This is the technical center of the release. A skill is not mainly an instruction sheet. It is a way to bind a task to its checks. For coding, that may mean Playwright, tmux, a checkout verifier, or a headless browser trace. For analytics, it may mean a semantic layer first, then curated domain docs, then adversarial review. For operations, it may mean a runbook that starts from a symptom and ends with a structured report.
The best skill is short at the top and deep underneath
Anthropic's advice is unusually concrete: do not state the obvious, build a gotchas section, use the file system for progressive disclosure, avoid railroading Claude, think through setup, write descriptions for the model rather than for humans, help Claude remember, store scripts, and use on-demand hooks 1.
The strongest of those is progressive disclosure. The blog shows a
SKILL.md acting as a hub that points to narrower files for specific symptoms. The docs recommend the same pattern: keep SKILL.md focused, move detailed API docs, examples, and scripts into supporting files, and keep the main file under 500 lines 2.Anthropic also warns against over-prescribing the procedure. A skill should give Claude the durable constraints and outcome shape, then leave room to adapt to the specific repo, data source, or incident. That is a subtle but important distinction: the skill should constrain failure modes, not freeze the agent into a brittle checklist 1.
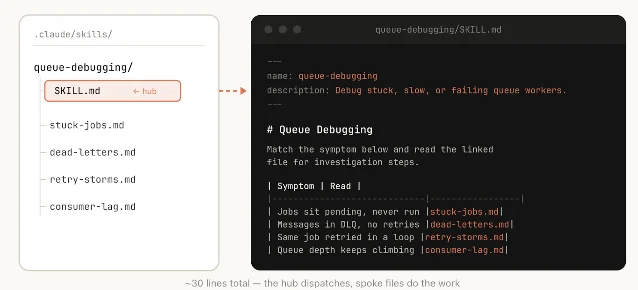
That pattern is a direct answer to context bloat. A team can put a large amount of institutional knowledge in the skill folder without forcing Claude to read all of it for every task. The agent loads the entrypoint, then follows pointers as the situation narrows. In practical terms, the skill folder becomes a small retrieval system with human-written routing rules.
The gotchas section is the second important pattern. Anthropic's example is not a vague style note. It is the sort of line a senior engineer writes after seeing the same bug three times: the subscriptions table is append-only, the row you want is the highest version rather than the latest
created_at; the same request ID has different field names across services; staging can return 200 even when the webhook did not process 1. That is exactly the kind of local, non-obvious knowledge LLMs tend to miss.Distribution is where this stops being personal prompt craft
The docs make skills available at several scopes: enterprise, personal, project, plugin, and nested project directories in monorepos 2. They also describe plugin marketplaces, where teams can distribute plugins containing skills, agents, hooks, MCP servers, or LSP servers through a
marketplace.json catalog 4. Anthropic's public anthropics/skills repository is already structured for that path: the README says users can add it as a Claude Code plugin marketplace and install document-skills or example-skills 5.That makes the rollout shape clearer. Individual users start by capturing the instructions they paste repeatedly. Teams then put project skills under version control. Larger organizations package reusable skills into plugins and marketplaces, with versioning, install flows, and update channels.
The risk is the same one that hits every internal platform: if the skill library grows without ownership, Claude inherits stale procedures at machine speed. Anthropic appears aware of this. Its analytics post says offline accuracy drifted from about 95% at launch to about 65% over a month before the team treated skill maintenance as an engineering problem; roughly 90% of its data-model PRs now include a skill change in the same diff 3.
That is the standard to watch. A skill marketplace without maintenance discipline becomes prompt sprawl. A skill marketplace tied to CI, evals, and ownership becomes something closer to an operating layer for agents.
What to watch next
Three questions will determine whether skills become a real enterprise primitive or stay a power-user feature.
First, can teams measure skill quality? Anthropic says it logs skill usage with a
PreToolUse hook to find popular or under-triggering skills 1. Usage is only the first metric. The harder one is whether a skill reduces wrong answers, wasted tool calls, or human rework.Second, can users trust the distribution layer? Plugin components can include hooks, MCP servers, LSP servers, monitors, and agents, not only markdown instructions 6. That power is useful, but it puts more pressure on review, permissions, and workspace trust.
Third, can skills remain portable? The Claude Code docs say skills follow the Agent Skills open standard, while Claude Code adds features such as invocation control, subagent execution, and dynamic context injection 2. The more a team relies on Claude-specific hooks and plugin machinery, the more useful the skills become inside Claude Code, and the less portable they may be elsewhere.
For now, the practical read is simple: if Claude keeps making the same mistake twice, that mistake probably belongs in a skill. If the fix requires a command, a verifier, a reference table, or a team-owned runbook, it definitely does.
Add more perspectives or context around this Post.